[프로그래머스] [1차] 캐시 (Java)
[프로그래머스] [1차] 캐시 풀이

◾ 문제
문제 설명
캐시
지도개발팀에서 근무하는 제이지는 지도에서 도시 이름을 검색하면 해당 도시와 관련된 맛집 게시물들을 데이터베이스에서 읽어 보여주는 서비스를 개발하고 있다.
이 프로그램의 테스팅 업무를 담당하고 있는 어피치는 서비스를 오픈하기 전 각 로직에 대한 성능 측정을 수행하였는데, 제이지가 작성한 부분 중 데이터베이스에서 게시물을 가져오는 부분의 실행시간이 너무 오래 걸린다는 것을 알게 되었다.
어피치는 제이지에게 해당 로직을 개선하라고 닦달하기 시작하였고, 제이지는 DB 캐시를 적용하여 성능 개선을 시도하고 있지만 캐시 크기를 얼마로 해야 효율적인지 몰라 난감한 상황이다.
어피치에게 시달리는 제이지를 도와, DB 캐시를 적용할 때 캐시 크기에 따른 실행시간 측정 프로그램을 작성하시오.
입력 형식
- 캐시 크기(
cacheSize)와 도시이름 배열(cities)을 입력받는다. cacheSize는 정수이며, 범위는 0 ≦cacheSize≦ 30 이다.cities는 도시 이름으로 이뤄진 문자열 배열로, 최대 도시 수는 100,000개이다.- 각 도시 이름은 공백, 숫자, 특수문자 등이 없는 영문자로 구성되며, 대소문자 구분을 하지 않는다. 도시 이름은 최대 20자로 이루어져 있다.
출력 형식
- 입력된 도시이름 배열을 순서대로 처리할 때, “총 실행시간”을 출력한다.
조건
- 캐시 교체 알고리즘은
LRU(Least Recently Used)를 사용한다. cache hit일 경우 실행시간은1이다.cache miss일 경우 실행시간은5이다.
입출력 예제
| 캐시크기(cacheSize) | 도시이름(cities) | 실행시간 |
|---|---|---|
| 3 | [“Jeju”, “Pangyo”, “Seoul”, “NewYork”, “LA”, “Jeju”, “Pangyo”, “Seoul”, “NewYork”, “LA”] | 50 |
| 3 | [“Jeju”, “Pangyo”, “Seoul”, “Jeju”, “Pangyo”, “Seoul”, “Jeju”, “Pangyo”, “Seoul”] | 21 |
| 2 | [“Jeju”, “Pangyo”, “Seoul”, “NewYork”, “LA”, “SanFrancisco”, “Seoul”, “Rome”, “Paris”, “Jeju”, “NewYork”, “Rome”] | 60 |
| 5 | [“Jeju”, “Pangyo”, “Seoul”, “NewYork”, “LA”, “SanFrancisco”, “Seoul”, “Rome”, “Paris”, “Jeju”, “NewYork”, “Rome”] | 52 |
| 2 | [“Jeju”, “Pangyo”, “NewYork”, “newyork”] | 16 |
| 0 | [“Jeju”, “Pangyo”, “Seoul”, “NewYork”, “LA”] | 25 |
주어진 도시 이름 배열을 순서대로 처리할 때, 지정된 캐시 크기(cacheSize)에 맞춰 LRU(Least Recently Used) 캐시 교체 알고리즘을 적용하여 총 실행 시간을 구하는 문제다.
◾ 알고리즘 [접근 방식]
가장 쉽게 떠오르는 방법은 역시나 캐시를 ArrayList 로 관리하는 것이다. 이 문제의 주요 로직을 살펴보고 ArrayList를 사용해도 되는지 확인해보자.
캐시에 특정 도시 존재여부 확인
: 리스트(캐시) 내에 특정 도시 이름이 있는지 찾는다.
→ 찾기 위해 처음부터 끝까지 순회해야 하므로 $O(N)$의 시간이 소요된다.캐시가 꽉 찬 경우 LRU 갱신
: 가장 오래된(리스트 맨 앞) 도시를 제거하고, 새로운 도시를 리스트 맨 뒤에 저장한다.
→ 리스트 맨 앞 요소를 제거하는 경우, 뒤에 있는 요소들을 앞으로 한 칸씩 당겨야 하므로 $O(N)$의 시간이 소요된다.캐시에 특정 도시가 존재하는 경우 LRU 갱신
: 리스트에서 특정 요소를 삭제하고, 다시 맨 뒤에 저장한다. (가장 최근 사용 처리)
→ 해당 요소가 있는 위치부터 뒤에 있는 요소들을 앞으로 한 칸씩 당겨야 하므로 $O(N)$의 시간이 소요된다.캐시가 꽉 차지 않았고, 특정 도시가 존재하지 않는 경우
: 리스트의 맨 뒤에 해당 도시를 추가한다.
→ 맨 뒤에 추가만 하면 되므로 $O(1)$의 시간이 소요된다.
따라서, 입력 하나당(cities 배열의 원소 한 개) 시간복잡도는 $O(N)$이다.
이 문제에서 cacheSize는 최대 30, cities배열의 길이는 최대 100,000이다.
따라서 최대 $30 \times 100,000 = 3,000,000$(300만) 번 내로 연산이 발생하므로, ArrayList 로 이 문제를 풀어도 제한 시간 내에 충분히 통과할 수 있다!
그래도 최적화 해보자
당장 이 문제에서는 $O(N)$의 시간복잡도로도 충분하지만, 나중에 입력이 더 크게 주어지는 문제를 만나게 될 때를 대비해서 $O(N)$ 이 아닌 $O(1)$ 로 해결할 수 있는 정석적인 LRU 알고리즘으로 이 문제를 해결해보자.
LRU란?
LRU(Least Recently Used) 알고리즘은 이름에서도 알 수 있듯이 한정된 캐시 공간이 가득 찼을 때 가장 오래전에 참조된 데이터를 방출하는 캐시 교체 정책이다. 가장 오랫동안 사용하지 않은 데이터가 미래에도 사용될 확률이 가장 낮을 거라는 시간적 지역성 원리에서 비롯된 전략이다.
작동 방식은 매우 간단하다.
- Cache Hit (캐시에 찾는 데이터가 있을 때)
- 해당 데이터를 캐시에서 가져온다.
- 이 데이터는 방금 사용되었으므로, ‘가장 최근에 사용된 데이터’ 이므로 가장 마지막 방출 순위로 지정한다.
- Cache Miss (캐시에 찾는 데이터가 없을 때)
- 해당 데이터를 캐시에 추가한다.
- 이때 캐시 용량이 꽉 찼다면, ‘가장 오랫동안 사용되지 않은’ 데이터를 삭제한 뒤 새로운 데이터를 캐시에 추가한다.
우리는 직접 구현한 이중 연결 리스트를 통해 LRU 알고리즘을 구현할 것이다. 가장 최근에 사용된 데이터는 리스트의 맨 뒤(tail)에, 가장 오랫동안 사용되지 않은 데이터는 리스트의 맨 앞(head)에 위치시켜 관리한다.
이중 연결 리스트 포스팅
[Data Structure] 이중 연결 리스트(Doubly Linked List)
HashMap
LRU 구현을 위해 이중 연결 리스트와 함께 HashMap 자료구조가 사용된다. 데이터가 캐시에 존재하는지 확인하는 용도로 사용된다.
map.get(key) != null-> 캐시에 해당 데이터 존재 O (해당 이름의 도시가 존재함)map.get(key) == null-> 캐시에 해당 데이터 존재 X (해당 이름의 도시가 존재하지 않음)
◾ 핵심 로직
Node클래스 정의: 데이터를 담을
key(도시 이름)와 함께, 앞 노드와 뒤 노드를 가리키는prev,next포인터를 갖는다.초기화 및 더미 노드 세팅
: 양 끝단에 빈 값을 가진
head와tail더미(Dummy) 노드를 둔다. 이렇게 하면 항상head,tail노드가 존재하기 때문에 삭제나 삽입하려는 노드가 양 끝에 존재하 지 검증하여 처리할 필요가 없다.head의 바로 뒤(head.next)는 가장 오래된 데이터가 위치한다.tail의 바로 앞(tail.prev)은 가장 최신 데이터가 위치한다.
Cache Hit 상황
: 입력된 도시를
Map에서 검색하여 노드를 찾는다. 찾은 노드는 연결 리스트의 가장 최신 위치(tail.prev)로 다시 삽입한다.Cache Miss 상황
- 현재 캐시 사이즈가 가득 찼다면, 가장 오래된 노드(
head.next)를 리스트와Map에서 모두 지운다. - 새로운 도시 이름으로
Node를 생성하여Map에 등록하고, 연결 리스트의 가장 최신 위치(tail.prev)로 삽입한다.
- 현재 캐시 사이즈가 가득 찼다면, 가장 오래된 노드(
cacheSize = 5 일때, 가득 찬 캐시(이중연결리스트) 구조

◾ 코드
핵심 메서드 코드
노드를 삭제하고 삽입하는 메서드의 로직이다. 이중 연결 리스트의 특성을 살려 포인터만 스와핑해줌으로써 삽입, 삭제를 $O(1)$ 만에 가능하게 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 특정 노드를 리스트에서 제거(분리)하는 메서드
private void removeNode(Node node) {
node.prev.next = node.next; // 이전 노드의 다음 -> 현재 노드의 다음 노드로 연결
node.next.prev = node.prev; // 다음 노드의 이전 -> 현재 노드의 이전 노드로 연결
}
// 특정 노드를 마지막(tail) 바로 앞에 삽입
private void addLast(Node node) {
Node lastNode = tail.prev; // 현재 리스트에서 가장 마지막에 있는 노드
lastNode.next = node; // 마지막 노드의 다음 -> 현재 노드로 연결
node.prev = lastNode; // 현재 노드의 이전 -> 마지막 노드로 연결
node.next = tail; // 현재 노드의 다음 -> tail로 연결
tail.prev = node; // tail의 이전 -> 현재 노드로 연결
// 최종적으로 현재 노드가 리스트의 마지막 노드가 됨
}
최종 자바 정답 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
import java.util.*;
class Solution {
// 이중 연결 리스트를 위한 노드 클래스 정의
class Node {
String key; // 도시 이름, 캐시에서 삭제시 Map에서도 함께 지우기 위한 용도
Node prev;
Node next;
public Node(String key) {
this.key = key;
}
}
Map<String, Node> map; // 캐시에 존재하는 노드 저장, 탐색용
// 이중 연결 리스트의 양 끝 엣지 케이스를 막기 위한 더미 노드
Node head;
Node tail;
int capacity; // 캐시 최대 크기
public int solution(int cacheSize, String[] cities) {
// 예외: 캐시 크기가 0이면 캐싱을 할 수 없으므로 전부 Cache Miss
if (cacheSize == 0) return cities.length * 5;
capacity = cacheSize;
map = new HashMap<>();
// 더미 노드 초기화 세팅
// head 쪽에 가까울수록 오래된 데이터, tail 쪽에 가까울수록 최신 데이터
head = new Node("");
tail = new Node("");
head.next = tail;
tail.prev = head;
int totalTime = 0;
for (String city : cities) {
// 대소문자 구분을 하지 않으므로 모두 소문자로 통일
String key = city.toLowerCase();
// 캐시 내에 존재하는 노드인 경우
if (map.containsKey(key)) {
Node node = map.get(key);
// 기존 위치에서 빼내서 가장 최근 위치(맨 뒤)로 갱신 이동
removeNode(node);
addLast(node);
totalTime += 1;
}
// 캐시 내에 존재하지 않는 노드인 경우
else {
// 캐시가 가득 찼다면 제일 오래된 데이터(LRU) 삭제 공간 확보
if (map.size() >= capacity) {
Node lruNode = head.next; // 삭제 대상 : head 바로 다음 노드(가장 오래된 노드)
removeNode(lruNode); // 연결 리스트에서 절단
map.remove(lruNode.key); // Map에서도 삭제
}
// 새로운 데이터 생성 및 최신 위치 삽입
Node newNode = new Node(key);
map.put(key, newNode);
addLast(newNode);
totalTime += 5;
}
}
return totalTime;
}
private void removeNode(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void addLast(Node node) {
Node lastNode = tail.prev;
lastNode.next = node;
node.prev = lastNode;
node.next = tail;
tail.prev = node;
}
}
◾ 결과
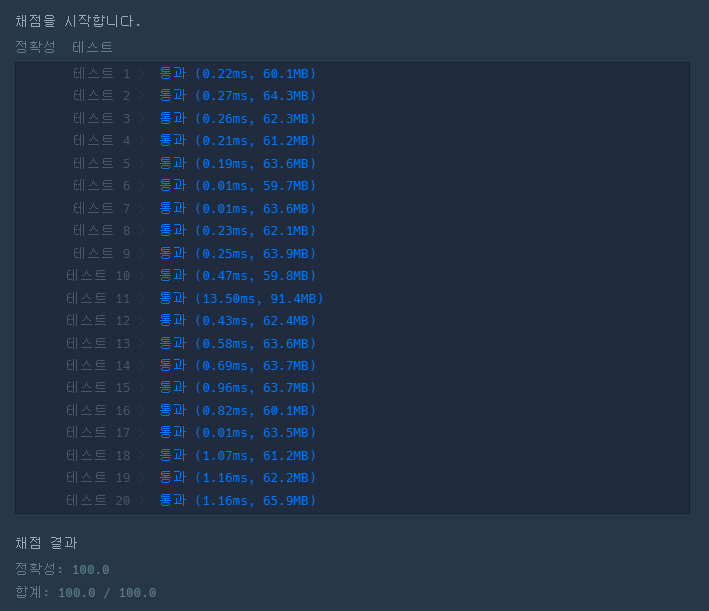
◾ 마무리
ArrayList 로도 충분해 풀 수 있는 문제였지만 직접 LRU 알고리즘을 구현함으로써 $O(N)$ → $O(1)$로 실행 시간을 획기적으로 단축해보았다.
댓글 0